JVM性能 #
知识点 #
- 查找CPU 100%
- top + jstack:通过top找到最繁忙的进程后再通过jstack找到对应线程。
- 内存泄露
- 多次执行jmap -dump,内存泄露的对象在此期间不会回收,而是一直增长。
- 如果应用奔溃没有捕获到内存数据,可以在启动参数加上OOM日志
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=<file-path>。
- 如果应用奔溃没有捕获到内存数据,可以在启动参数加上OOM日志
- 多次执行jmap -dump,内存泄露的对象在此期间不会回收,而是一直增长。
GC性能 #
调优前提 #
程序已没有可以改进的地方了。一个有缺陷的系统是不能指望依赖调优来解决性能问题的。
调优关注点 #
- 停顿时间(延迟):垃圾回收引起的应用停顿时间。停顿时间越短响应速度越高,用户体验更好。
-XX:MaxGCPauseMillis,默认为200ms。
- 吞吐量:单位时间内应用运行时间的占比。吞吐量越高,CPU利用率越高,完成任务越快。
- 计算公式:吞吐量 = 应用运行时间 / (应用运行时间 + 垃圾收集时间)
-XX:GCTimeRatio=n,默认为12,表示92.3%的时间花在运行应用上。当值设为20时,表示95%时间应用于应用程序上。
- FGC次数:FGC会引起长时间STW,因越少越好。一般1天最多1次,使用G1时应该更少。
jstat #
实时监控GC状态。
jstat -gcutil <pid> <sec>
GC日志 #
开启GC日志需要在项目启动命令中加入以下参数:
- 对于 Java1.4、5、6、7、8,将以下 JVM 参数传递给您的应用程序即可: -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:
- 对于 Java 9,传递以下 JVM 参数: -Xlog:gc*:file=
file-path: 写入 GC 日志文件的位置
GC日志会受到磁盘I/O的影响,如果磁盘I/O过重,GC日志写入可能会造成应用的长暂停,所以最好把GC日志写到单独的SSD硬盘上。
GCeasy #
图表解析
总览和建议

由于多线程GC原因,一般情况下real<=user+sys。当出现real>user+sys时,可能有以下原因。
- I/O频繁。HotSpot JVM上GC(logging)线程可能会因后台磁盘I/O线程被阻塞。应该尝试减少I/O线程或转移到单独的服务器上。减少同服务器上I/O密集型的程序数量,减少其它日志记录,将GC日志记录在专用的HDD或成本更高的SSD上。
- 没有足够的CPU。服务器上可能有多个应用程序导致CPU利用率过高,应用就没有足够的CPU来运行。应该减少当前服务器的进程数量或者提高服务器的规格。
当出现sys > user时,可能有以下原因:
- 操作系统问题:确保操作系统是否正常运行,有最新补丁,内存、磁盘等空间足够。
- 虚拟机问题:确保虚拟机有足够资源运行。
- 内存约束。如果操作系统无法找到连续可用的空间类分配页空间,则操作系统可能会停止所有运行进程,移动数据以产生连续空间。这种情况下需要确保内存足够或减少其它进程数量。
- 磁盘I/O压力。
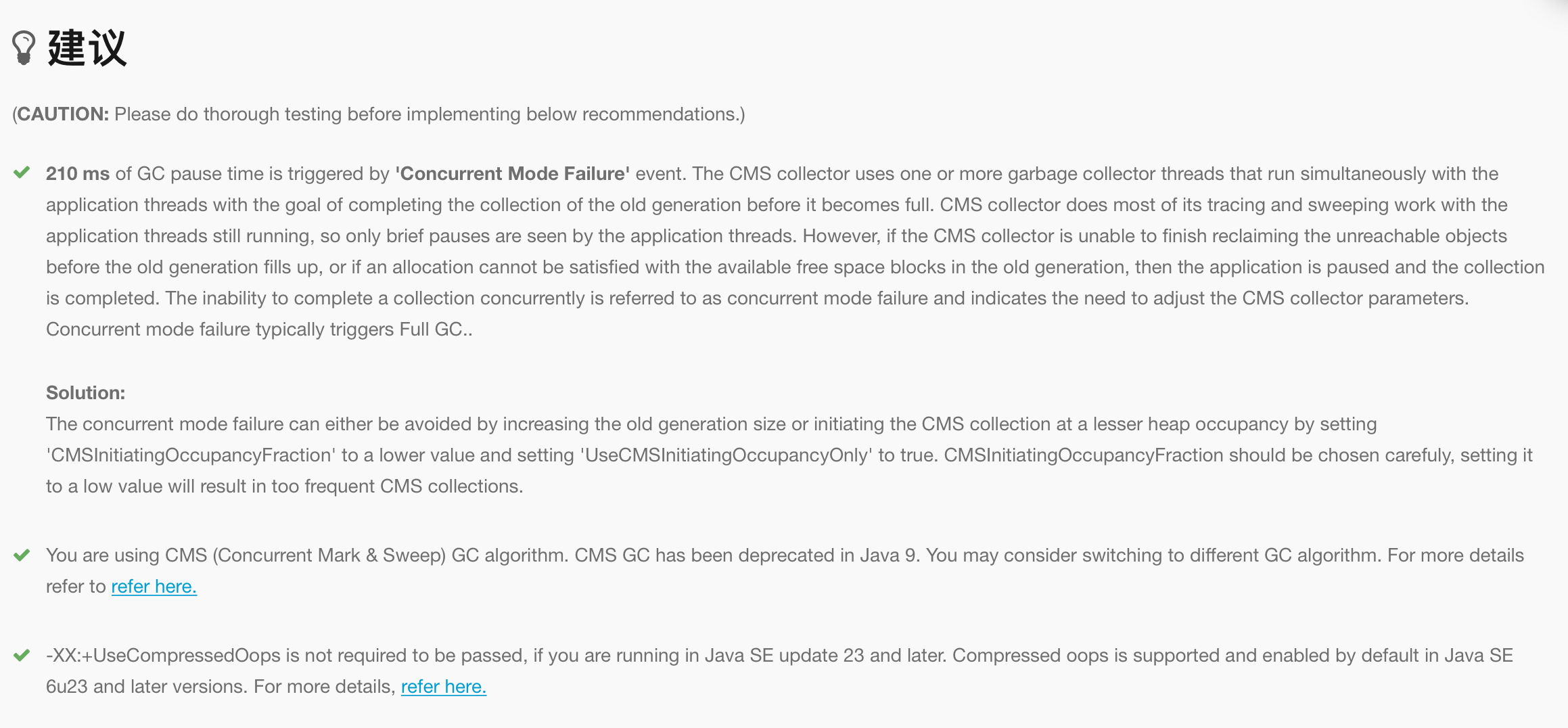
- Concurrent Mode Failure:并发收集失败。CMS采用多线程并发进行收集,期间应用线程也在同时运行。如果CMS无法及时完成对象的收集就会退化为旧的并行收集器进行FGC。可以通过增加老年代大小或者设置CMSInitiatingOccupancyFraction为较低的值让CMS提前启动以及将UseCMSInitiatingOccupancyOnly设为true。需要注意如果CMSInitiatingOccupancyFraction太低就会频繁进行GC。
- Metadata GC Threshold:元空间GC。原因可能为元空间太小或存在类加载器泄露(可能性很小)。可以通过设置“-XX:MetaspaceSize”增加元空间大小。
- G1 Humongous Allocation:G1 H分配。大对象指分配空间超过region一半大小的对象。频繁的分配大对象会导致两个性能问题,大对象不足region空间的部分不会被使用,易造成内存碎片;JDK 1.8u40之前大对象空间只在FGC时回收。可以通过增加region大小,避免对象超过50%的大小限制。region默认情况下是在启动期间根据堆大小计算的。可以通过指定“-XX:G1HeapRegionSize”属性来手动指定。值需要在1到32MB之间,并且是2的幂。
- G1 Evacuation Pause:G1暂停事件。将存活对象从一组region复制到另一组region时会触发。
- 内存方面只设置堆的最小或最大空间以及暂停时间,避免手动设置年轻代和老年代大小。
- 如果问题仍然存在,增加堆大小。
- 如果无法增加堆大小,并且注意到标记周期开始得不够早,无法回收旧一代,请减少-XX:InitiatingHeapOccupancyPercent。默认值为45%。减小该值将提前开始标记循环。另一方面,如果打标周期开始较早且未回收,则将-XX:InitiatingHeapOccupancyPercent阈值提高到默认值以上。
- 还可以增加-XX:ConcGCThreads的值增加并发标记的线程数量。
- 增加“-XX:G1ReservePercent”参数的值。默认值为10%。这意味着G1垃圾收集器将始终保持10%的内存可用。当您尝试增加此值时,GC将提前触发,从而阻止疏散暂停。注:G1 GC将该值上限为50%。
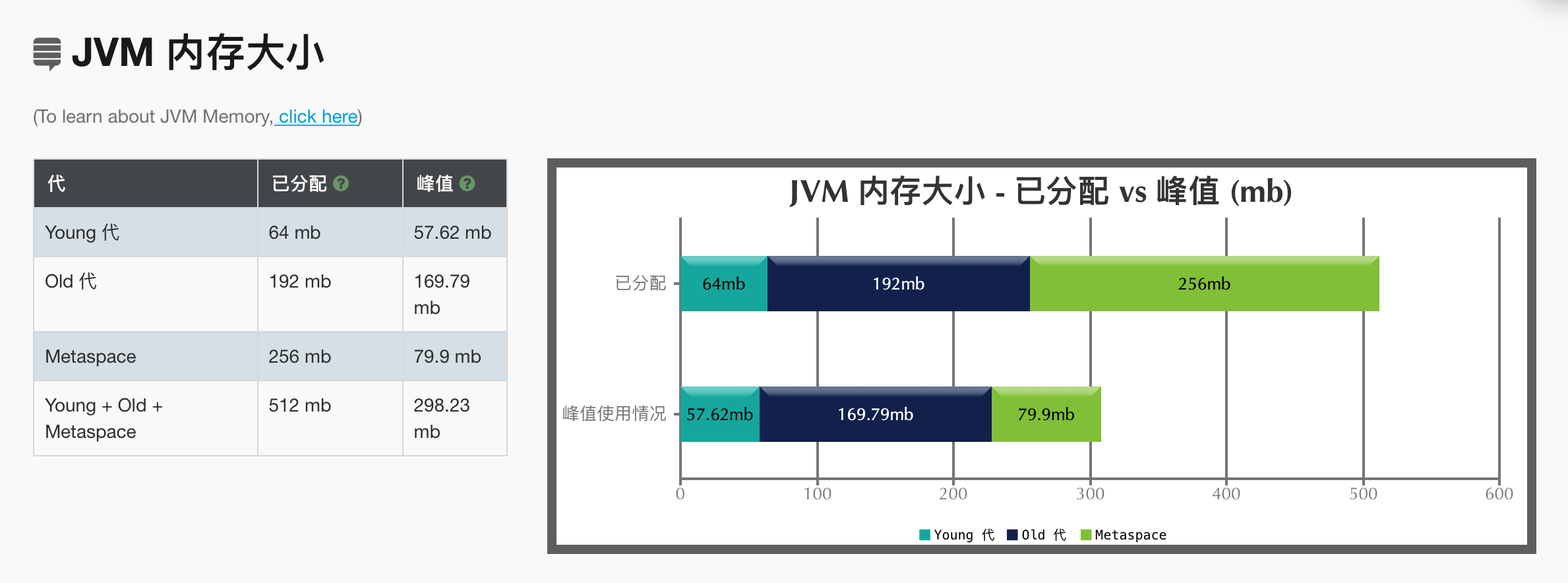
内存大小信息
关键性能指标
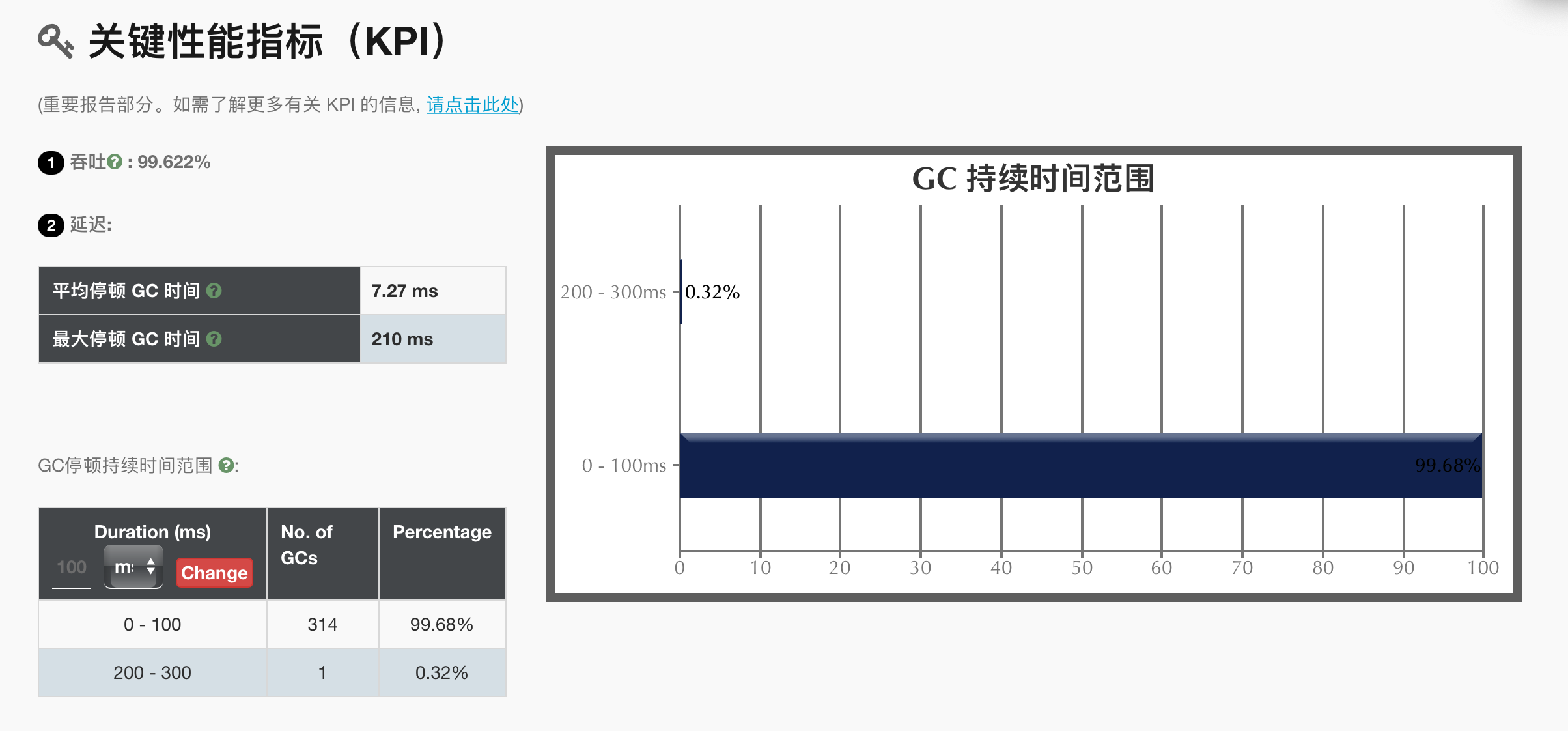
- 吞吐量(Throughput):指定时间内完成的工作量。通常应该达到95%以上。
- 工作量可以分为生产性工作(应用线程)和非生产性工作(GC线程)两种。如果程序运行了60分钟,其中2分钟用于GC,则GC工作量占2/60=3.33%,则程序吞吐量为100-3.33=96.67%。
- 延迟(Latency):单次GC耗时。
- GC持续时间范围表示在指定时间范围内完成了多少次GC。
- 轨迹(Footprint):CPU消耗。Footprint需要使用诸如Nagios, NewRelic, AppDynamics等工具来查看。一些GC算法将消耗更多的CPU(如并行、CMS),而其他算法(如串行)将消耗更少的CPU。
根据内存调优准则,吞吐量、延迟和CPU消耗一次只能选择其中的两个:
- 如果您想要良好的吞吐量和延迟,那么占用空间将牺牲。
- 如果您想要良好的吞吐量和占用空间,那么延迟将牺牲。
- 如果您想要良好的延迟和占用空间,那么吞吐量将牺牲。
交互图
GC后堆内存大小
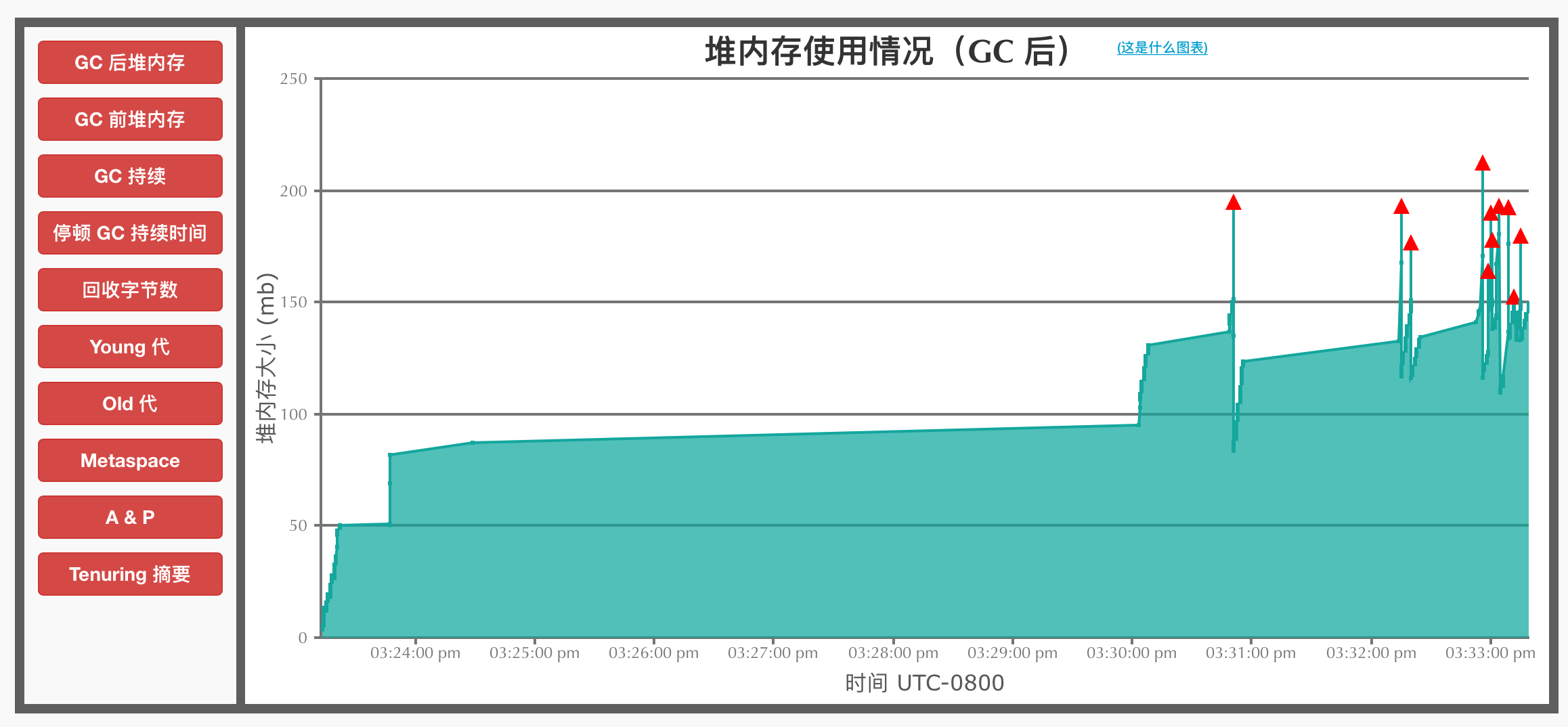
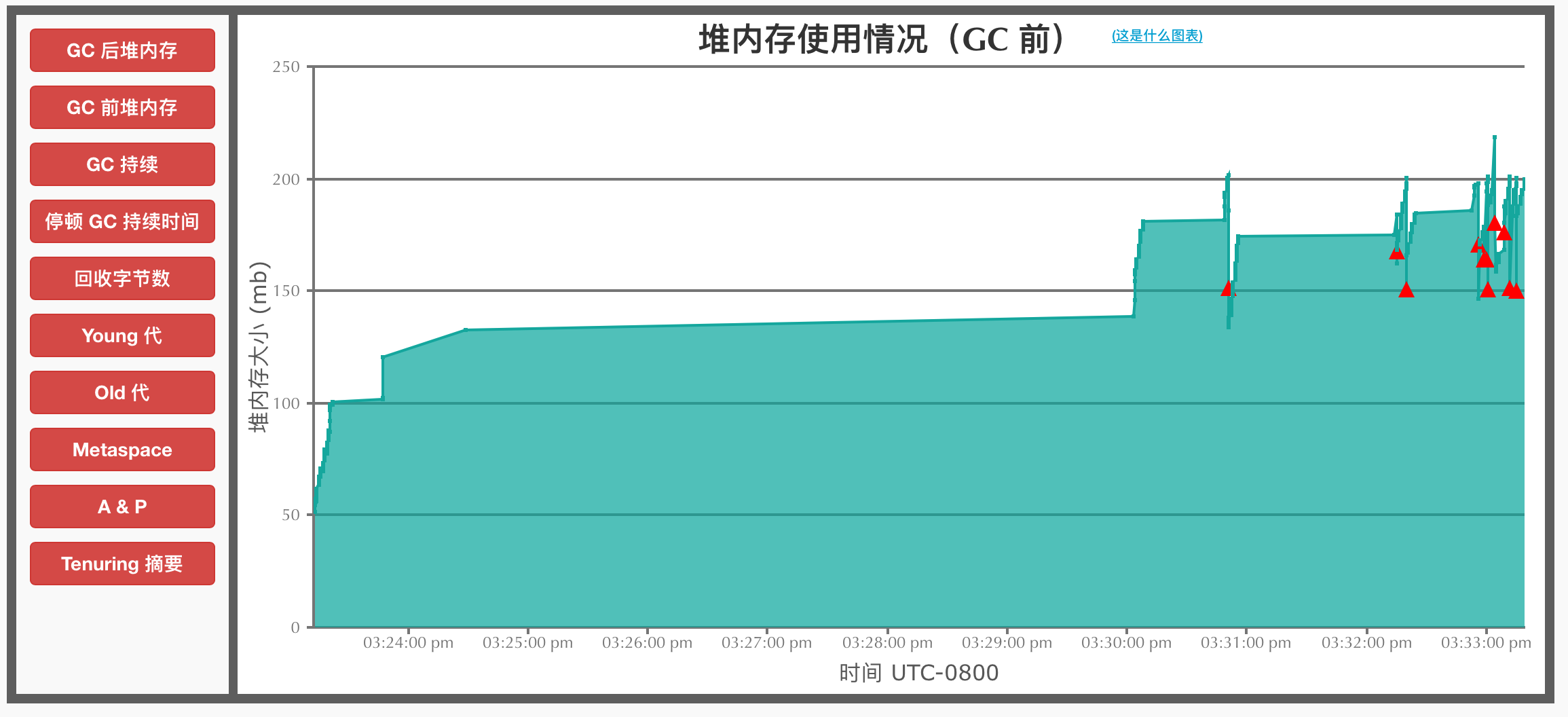
绿色拐点为YGC,红色标示的为FGC。
GC前堆内存大小
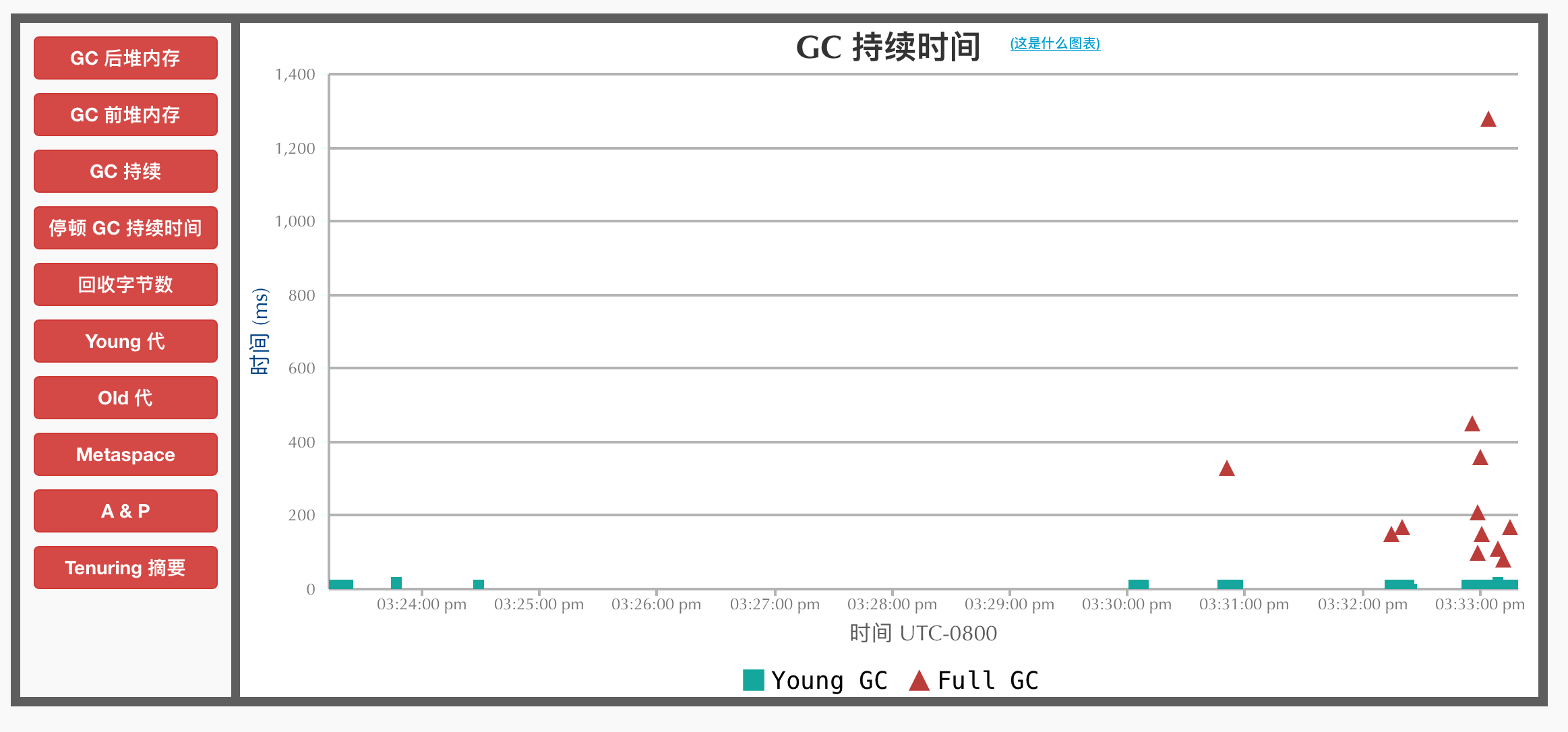
GC持续时间:整个GC的耗时。
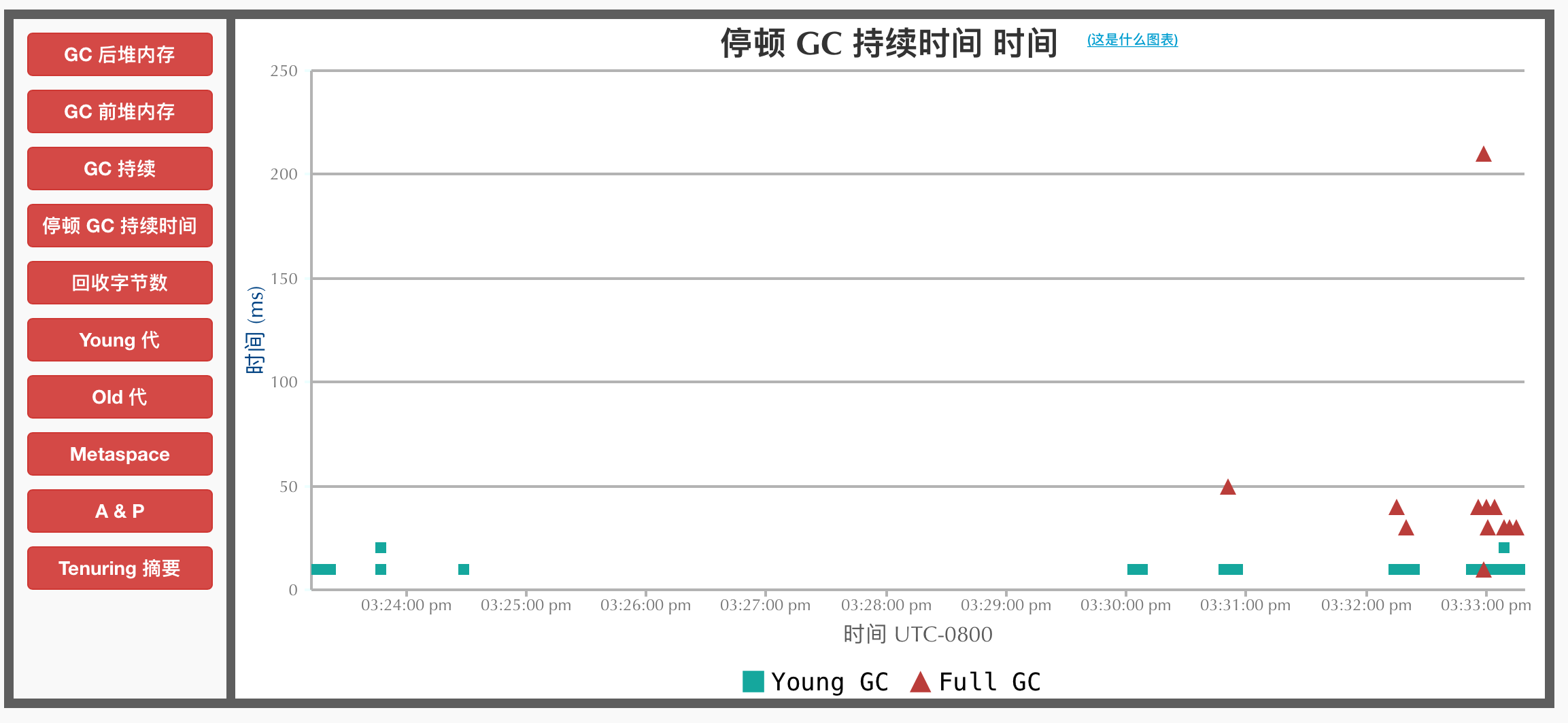
停顿GC持续时间:整个GC中STW阶段的耗时。
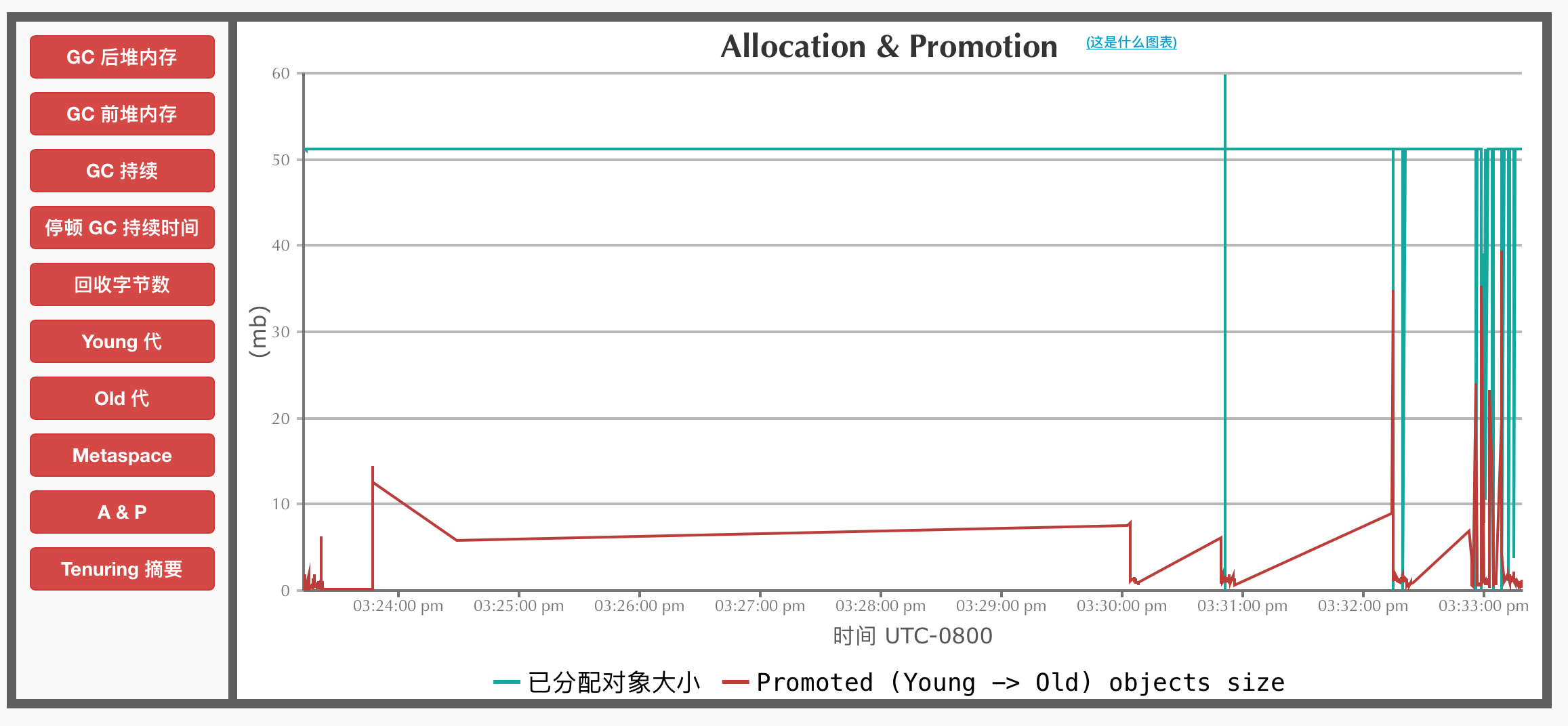
A & P
每次GC的时候堆内存分配和晋升情况。其中红色的线表示每次GC的时候年轻代里面有多少内存(对象)晋升到了老年代。
GC统计数据
基于real时间统计,而非user和sys。一次GC可分为user、sys和real三种类型。例如:Times: user=11.53 sys=1.38, real=1.03 secs。命令行执行time可以看到区别。
- Real:时钟时间,即调用从开始到结束的时间。比较接近真实的GC时间。
- User:用户时间,内核外进程执行时实际使用的CPU时间(多核为相加之和),不包含CPU被挂起等待的时间。
- Sys:系统时间,进程在内核中花费的时间。User+Sys为进程实际使用了多少CPU时间。单线程GC时Real和User+Sys之和相近。但是当采用多核多线程GC时,由于工作负载在这些线程间共享,总CPU时间可能会远超过时钟时间。
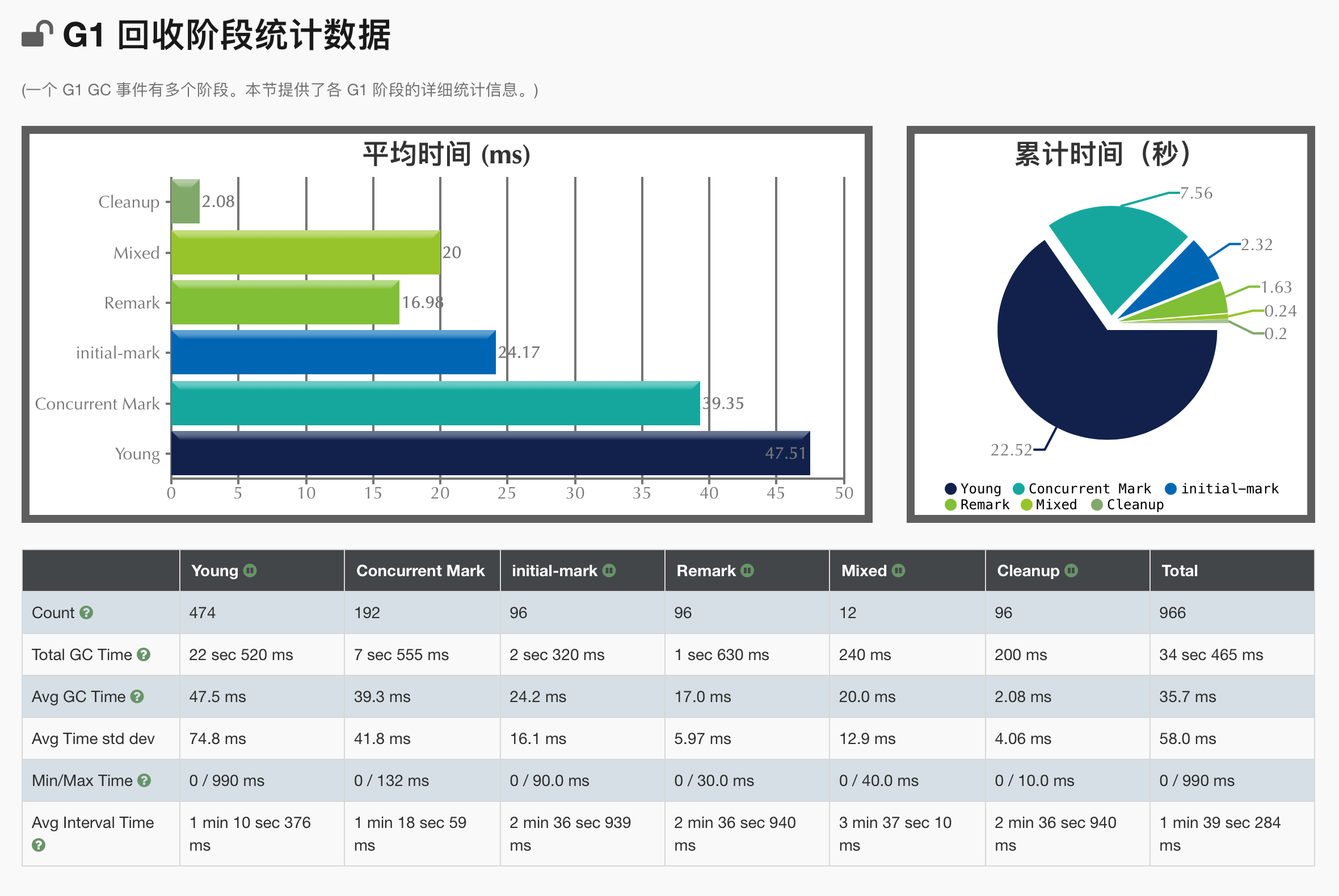
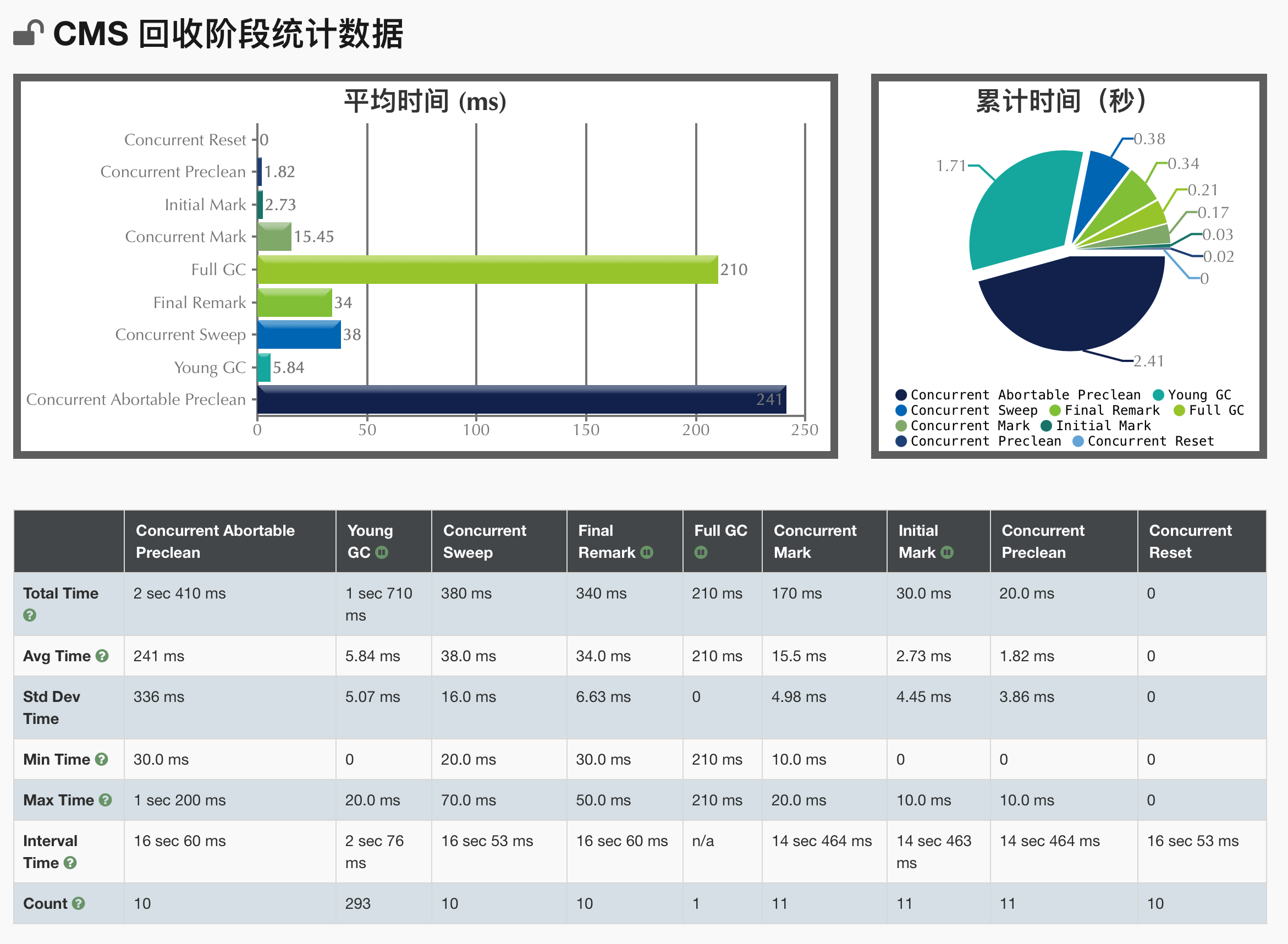 以上有停止标识的会STW,共有YGC、最终标记、初始标记、FGC四种。
以上有停止标识的会STW,共有YGC、最终标记、初始标记、FGC四种。
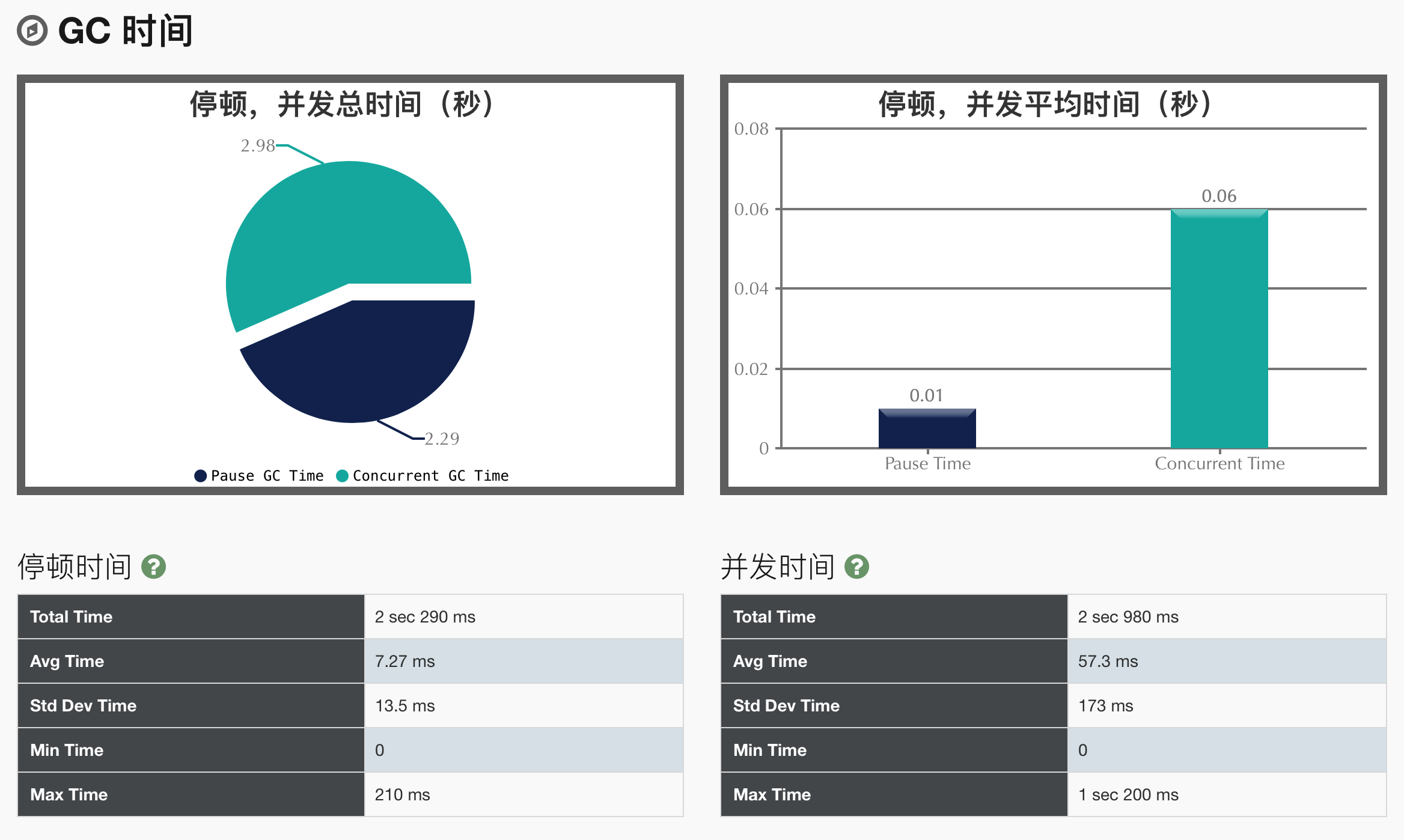
GC时间
- CMS STW时间为三种:YGC、第一次标记、最终标记。上面的Total Time为总和。
- G1不引起STW的并发时间为:并发标记、Concurrent PreClean、Concurrent Abortable PreClean、并发扫描、Concurrent Reset。
对象数据
以下参数依次为总创建对象字节数、总年轻代到老年代提示对象字节数、对象平均创建速率、对象平均提升速率。

GC原因

常见GC原因如下:
- Allocation Failure:年轻代没有足够空间分配内存。
- Full GC - Allocation Failure:原因有两种:分配太多对象来不及收集或老年代存在大量碎片空间。
- Concurrent Mode Failure:并发回收失败,CMS未能在并发情况下及时回收空间。
- G1 Evacuation Pause:Region复制。YGC和Mixed GC时触发。
- G1 Humongous Allocation
- GCLocker Initiated GC:JNI对应的region被释放。
- Metadata GC Threshold:元空间不足或类加载器泄露(可能性小)。
- Ergonomics:动态调整堆空间以满足预期的吞吐量或暂停时间。
GCViewer #
官网: https://github.com/chewiebug/GCViewer
图表解析
Chart
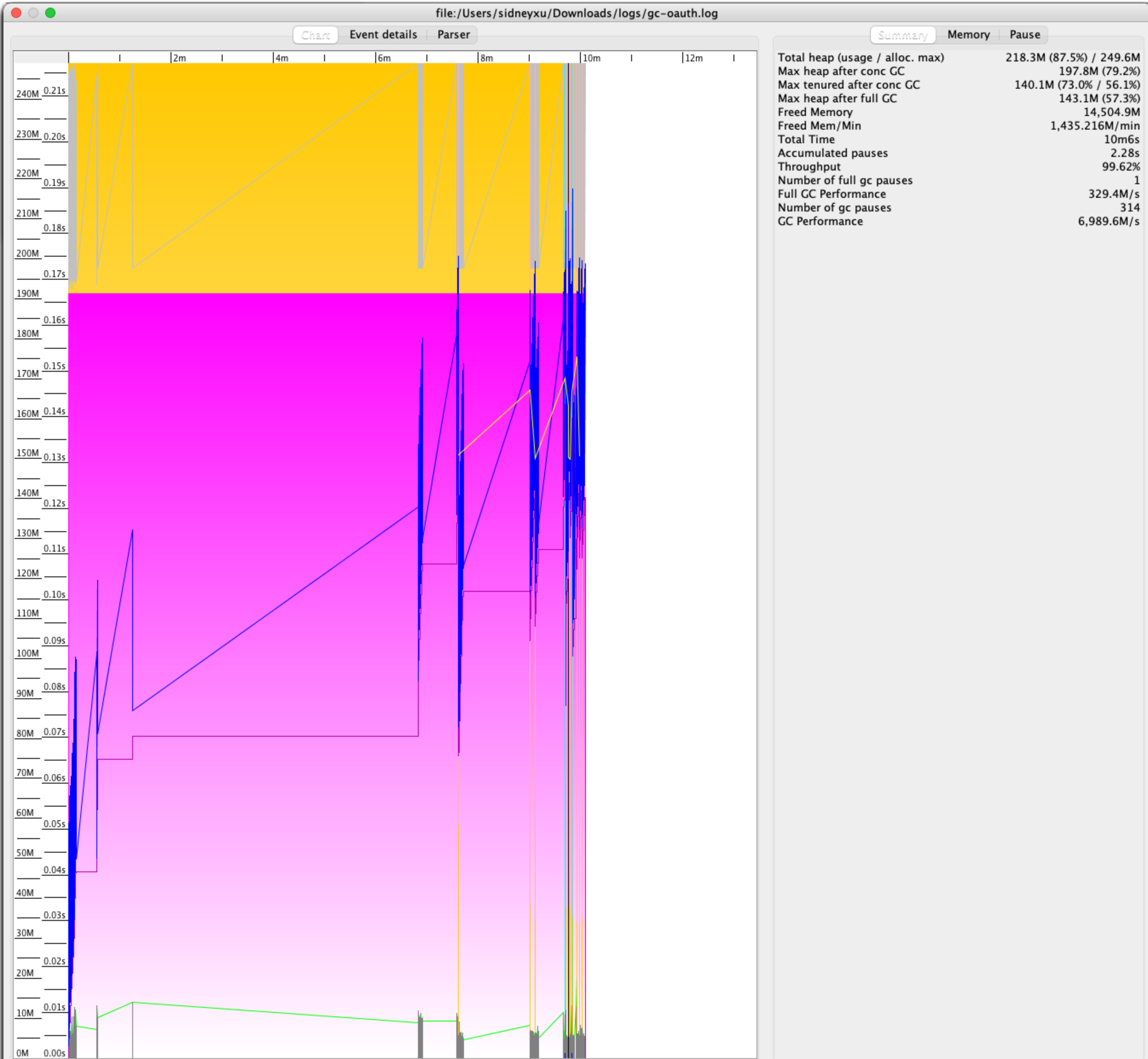
- 洋红色:老年代堆空间
- 橘黄色:年轻代堆空间
堆空间
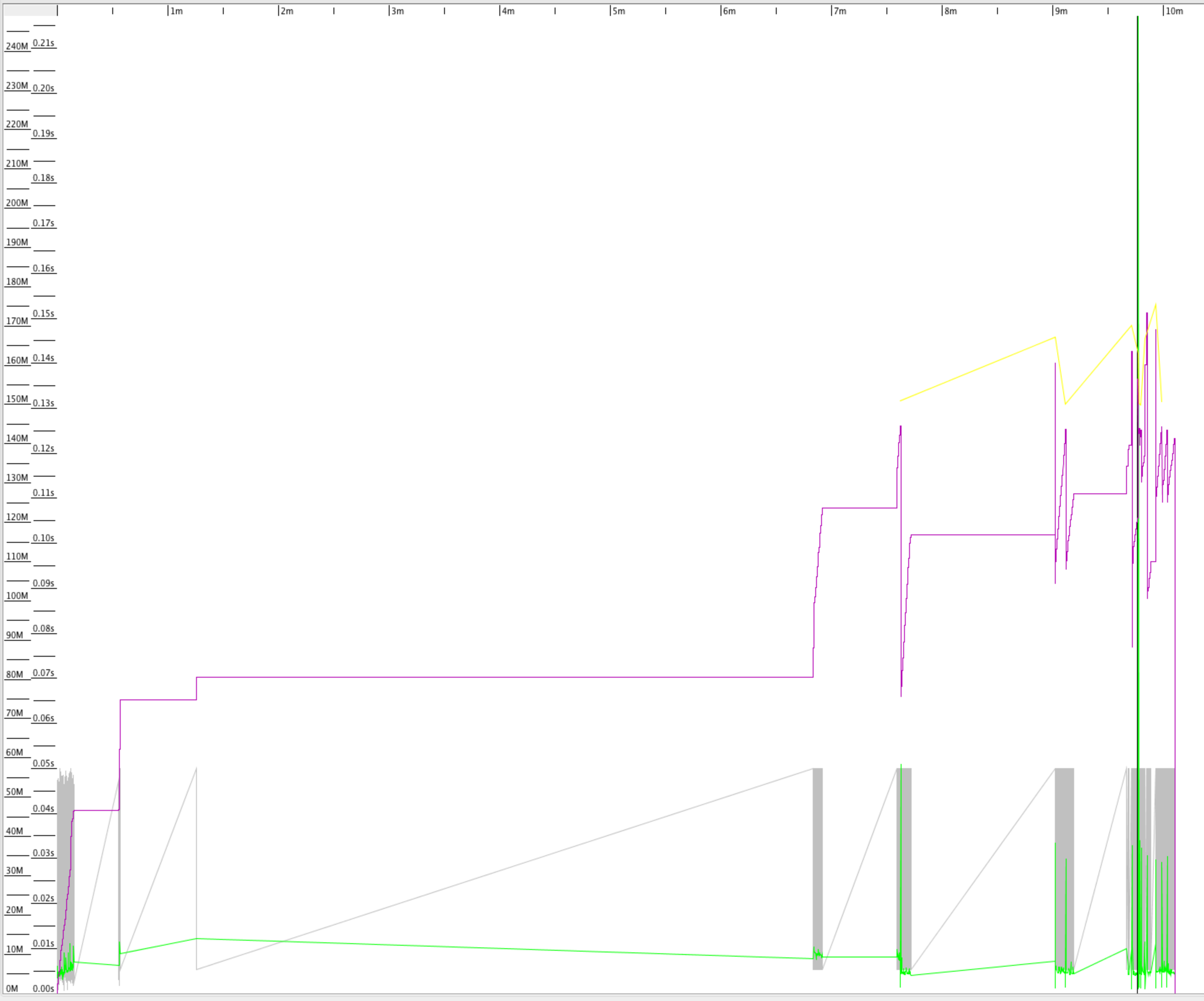
- 垂直黑线:FGC
- 绿线:GC Times Line
- 紫线:已使用老年代
- 灰线:已使用年轻代
- 黄线:Initial mark level,初始标记时会STW。
从图上可以看到以下信息:
- 随着YGC的运行,年轻代(灰色)开始回收,并周期性上下震荡。
- 每次年轻代满时,老年代(紫色)的空间使用率开始增加。
- 当Initial mark level(CMS)开始时,老年代也开始回收。
- 当空间满时,绿线贯穿了内存空间,FGC开始运行。
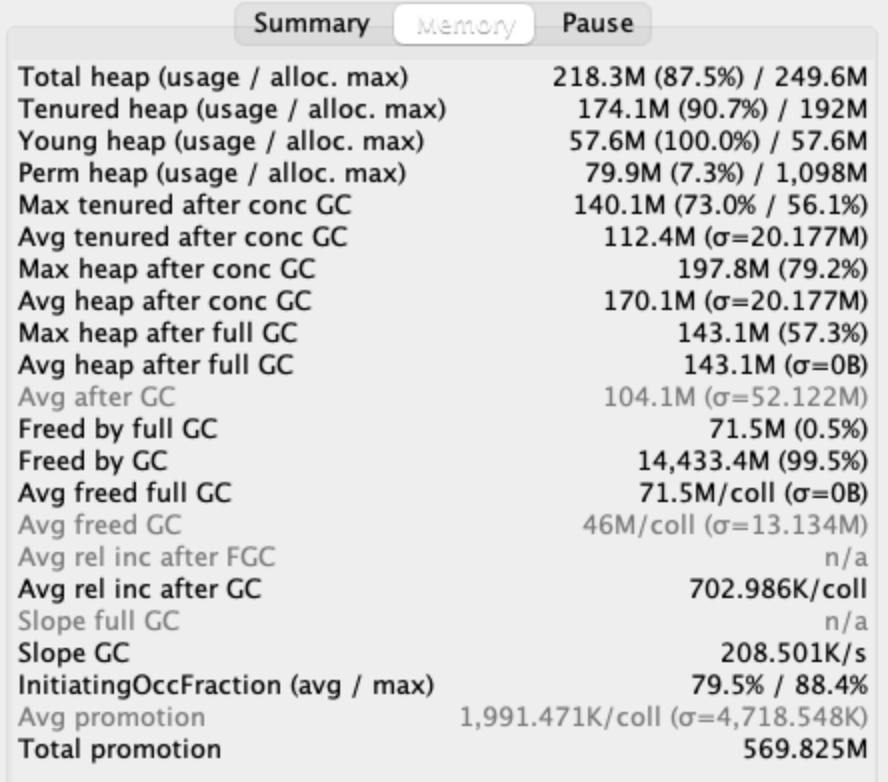
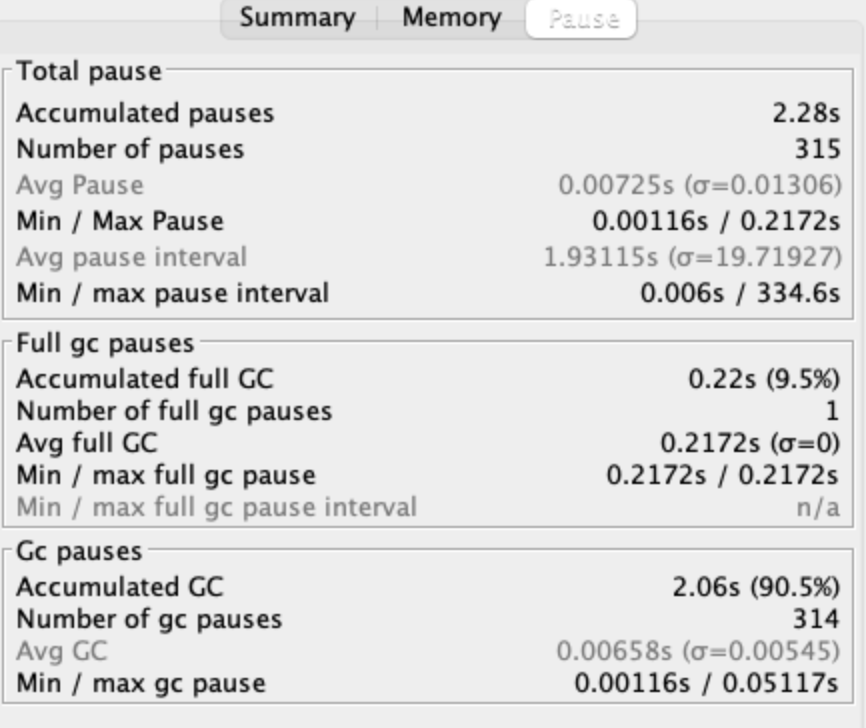
Summary
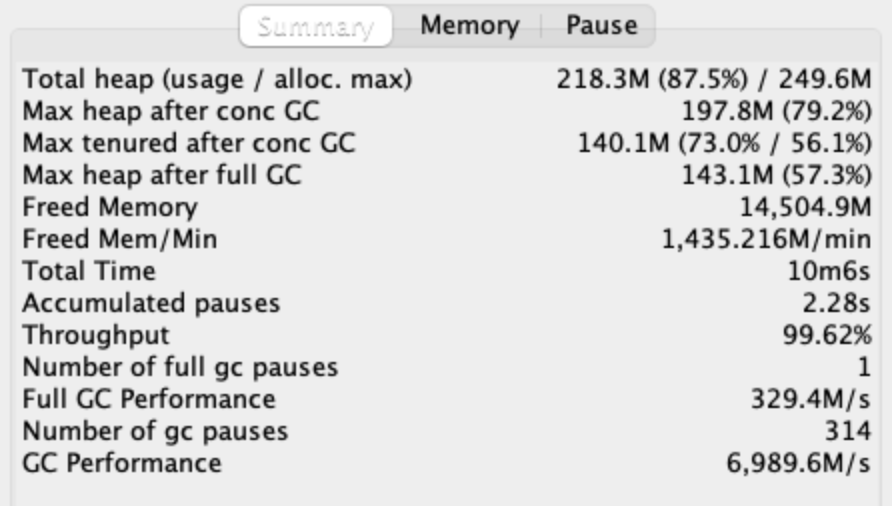
Memory
Pause
Event Details
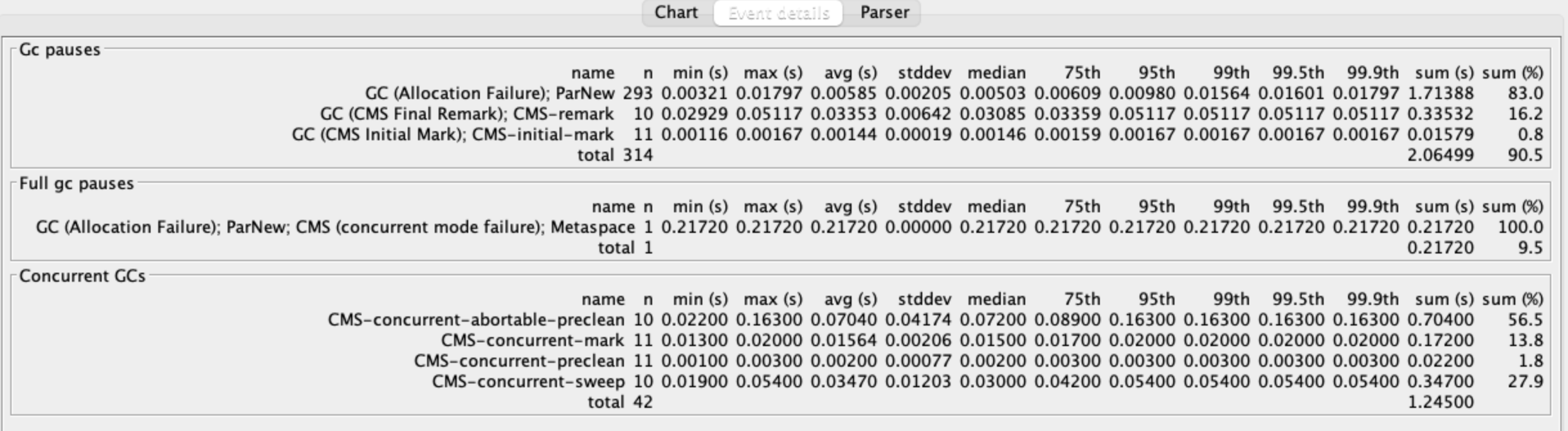
VisualVm #
图表解析
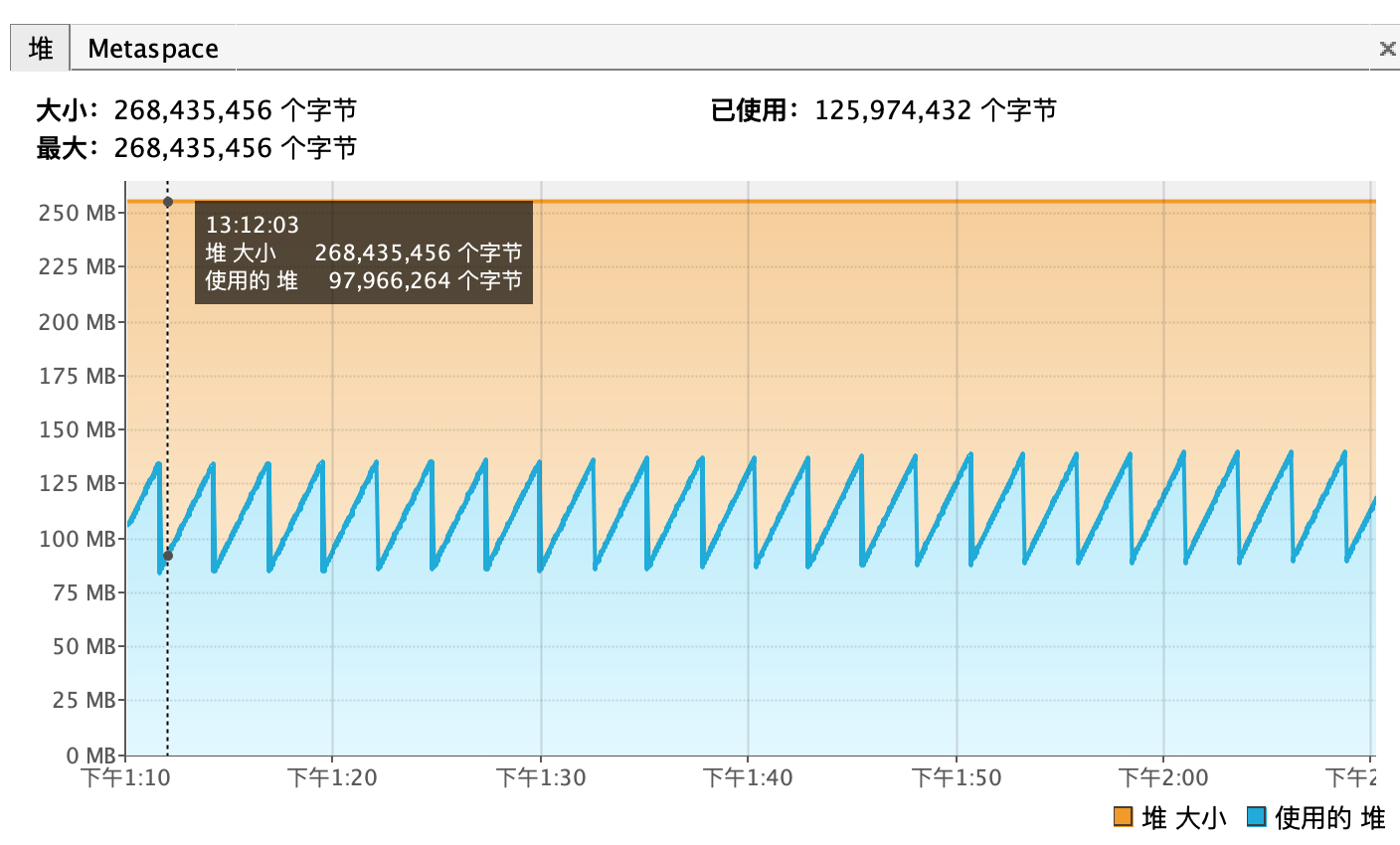
堆内存 #
调优关注点 #
- 对象创建速率
- 内存泄露
jmap #
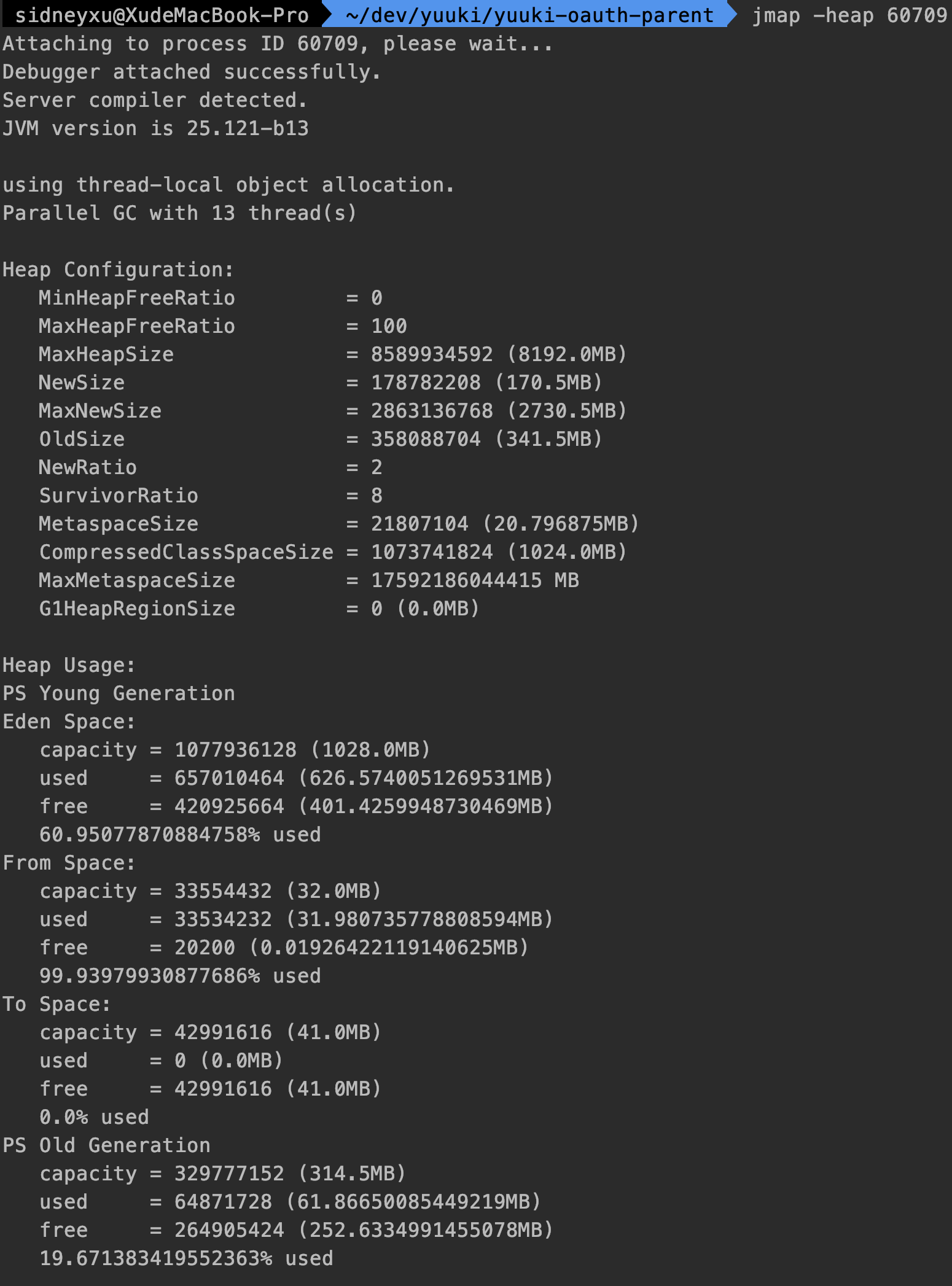
查看堆信息。
jmap -heap <pid>
导出堆信息,导出后的文件可以放入MAT来查看。
jmap -dump:format=b,file=<hprof_filename> <pid>
如果因为应用奔溃无法捕获到内存数据,可以在应用的启动参数加上开启OOM日志。需要注意这种方式可能会影响其它容器的运行。
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=<file-path>
实例
MAT #
建设中。。。
HeapHero #
线程栈 #
调优关注点 #
- 线程状态:阻塞和死锁可能会使应用失去响应。
jstack #
建设中。。。