系统设计大纲 #
项目分析 #
- 背景评估:为什么要做。
- 可行性评估:能不能做,值不值得做。
- 结果评估:要不要做,怎样算成功。
- 风险评估:人员、时间、技术。
- 复杂度评估:核心功能和难点。
容量评估 #
容量评估前需要先从产品或运营那里获得相关数据规模,如预计新增用户数、上架产品数等。为了简化计算,1024可按1000来计算。
存储量预估 #
常见字段类型的占用空间
- 数值型:tinyint 1个字节、int 4个字节、bigint 8个字节、decimal(m, d)为 m+2 个字节。
- 时间型:datetime 8个字节,timestamp 4个字节。
- 字节流型:blob最大64k,longblob最大4g。
字段数量暂时无法确定时可以按一行记录500字节来估算,此时单表1000W数据占用空间为5G。
缓存量预估 #
按照2-8法则,缓存一般最多存储数据总量的20%。
带宽预估 #
出口带宽 = QPS * 每条数据的占用空间
假设每条数据占用500字节,则QPS为20k时所需出口带宽为10MB/s。
压力测试 #
- 约束条件:RT、CPU利用率、内存占用、带宽占用、错误率、磁盘I/O利用率等。
- DID原则:Design(D)设计20倍的容量;Implement(I)实施3倍的容量;Deploy(D)部署1.5倍的容量。
实施步骤
- 明确约束条件。压测时只要有一项达到临界值就停止压测。将当前指标作为集群的最大处理能力。
- 做好压测数据隔离。对压测流量进行染色,例如在请求头上添加压测标记,通过网关进行分流。
- 压测数据入库通常有三种方式:
- 写入影子库。数据清理方便,应用层需要多使用一套数据库连接池。
- 写入入不同表。
- 写入同张表,通过特殊字段区分压测数据和普通数据。
- 调用其它服务时注意对不能压测或不用压测的组件做Mock或特殊处理。比如服务调用推荐系统、用户画像、大数据分析等系统时,将压测数据发送到Mock系统而不是真实服务。
- 确保下发压测数据的节点贴近用户,为保证真实性,避免和服务器在同一机房。
单机压测
- 选择一台相当于线上配置的机器进行压测。单机压测实施简单,一般用于项目未上线前。
集群压测
- 复制集群,对整个集群进行压测,并不断把线上集群的节点摘除,以减少机器数的方式增加线上节点单机的负荷。由于是完全使用线上真实流量进行压测,所以获取的单机最大容量数值更精确。
压测数据的产生
- 实时流量复制。复制请求同时进行流量清洗,去除无效请求。需要选择流量较大的时候执行。
- 模拟请求。实现简单,但数据通常无法反应真实情况。
- 流量工厂重放(日志重放)。将入口流量拷贝一份,批量在请求头添加压测标记,经过流量清洗后保存到NoSQL服务器中,作为流量数据工厂存储。压测时从流量工厂中取数据。流量工厂可以使用GoReplay。
水位标准
项目上线后,根据水位标准(致命线和安全线)来决定是否应该扩容或者缩容。当集群的水位线位于致命线以下时,就需要立即扩容,一般按固定数量或比例进行扩容。当水位线回到安全线以上并保持一段时间后,就可以进行逐步缩容,每次缩容一部分,节省成本。
- 单机能力=单机压测阀值qps
- 单机负荷=前一天单机最大qps
- 集群能力=单机能力*集群内机器数
- 集群负荷=前一天集群最大qps
- 单机水位=单机负荷/单机能力*100%
- 集群水位=集群负荷/集群能力*100%
- 理论机器数=集群负荷实际机器数/(集群能力标准水位),即监控数据/压测数据
- 机器增加=理论机器数-实际机器数
- 单机房上限/标准/下限水位为:80%、70%、50%
- 双机房上限/标准/下限水位为:55%、40%、30%
- 三机房上限/标准/下限水位为:75%、60%、50%
为了使容量评估更精确,可以采用区间加权来计算,也就是把请求按照响应时间分成多个区间,每个区间分别赋予不同的权重。响应时间越长权重越高,即占用资源越多,比如 0~10ms 区间的权重是 1,10~50ms 区间的权重是 2,50~100ms 区间的权重是 4,100~200ms 区间的权重是 8,200~500ms 区间的权重是 16,500ms 以上的权重是 32。因此单机的最大容量,也就是压测停止时刻采用区间加权方式计算得出。
服务调用设计 #
服务间数据一致性 #
建设中。。。
聚合查询 #
方案一览:
- A服务调用B服务后,聚合B的结果后返回。
- 由独立的聚合服务调用A服务和B服务后聚合返回。
- A服务和B服务将数据同步到聚合服务,由聚合服务返回。
- 聚合服务通过只读权限跨库查询。
Fallback处理 #
方案一览:
- 快速失败。
- 写操作优先采用快速失败。
- 业务异常优先采用快速失败。
- 重试。
- 读操作可以进行重试。
- 写操作如果要重试必须实现幂等性。
- 网络异常等非业务异常情况下可以重试。
- 系统繁忙等异常需要等待一段时间重试。
- 为避免重试放大引起的系统奔溃,应采用指数退避或者加重试间隔中加入抖动(随机噪声)。
安全机制 #
- 防止数据篡改:将请求中的参数进行排序后加密获得签名后一起发送。服务端同样将参数排序后加密,校验签名是否一致。
- 防止重放攻击:参数中加入时间戳后发送,服务端检查时间戳是否在有效的执行时间范围内。也可以请求分两步,客户端先获取token,获取成功后再发送真实数据+token,服务端检查token是否已被使用。
- 中间人攻击:窃取用户cookie发送给服务端。使用https,将服务端设置cookie为setSecure=true,这样cookie只在https中有效
- XSS:跨站脚本攻击,用户访问嵌入恶意代码的网站。设置setHttpOnly=true,让JS无法操作cookie,客户端保证任何返回内容都经过escapeHtml操作,过滤掉请求中的存在 XSS 攻击风险的可疑字符串。WebView页面可以注入特殊代码。服务端也可以创建XSSFilter。
- CSRF :跨站请求伪造,无需拿到用户信息,只要某个用户以登录状态访问网站A后再访问恶意网站,恶意网站引导用户访问网站A。和cookie不同浏览器l不会自动带入token。也可以采用Double-Submit Cookie,执行敏感操作时要求再次登录或输入操作密码。将Token保持在LocalStorage中也可以避免CSRF。
数据库设计 #
建模方法 #
- 恩门建模:自顶向下,从数据源开始。基于关系构建,冗余数据少,适合金融等应用场景固定的业务。
- 例:买家、商品是实体,买家购买商品是关系,所以DB应有买家表、商品表、买家商品交易表。
- 金博尔建模:自底向上,从数据分析需求开始,关心事实在不同维度下的结果。冗余数据较多,适合快速变化的互联网业务。
- 例:用户、商品是维度,库存和账号余额是事实,所以DB应有用户维度表、商品维度表、账号余额事实表、商品库存事实表。可以在账号余额事实表中添加商品ID来同时分析交易金额和账号余额。
高可用设计 #
容错方案 #
- 隔离机制
- 超时机制
- 降级机制
- 熔断机制
- 限流机制
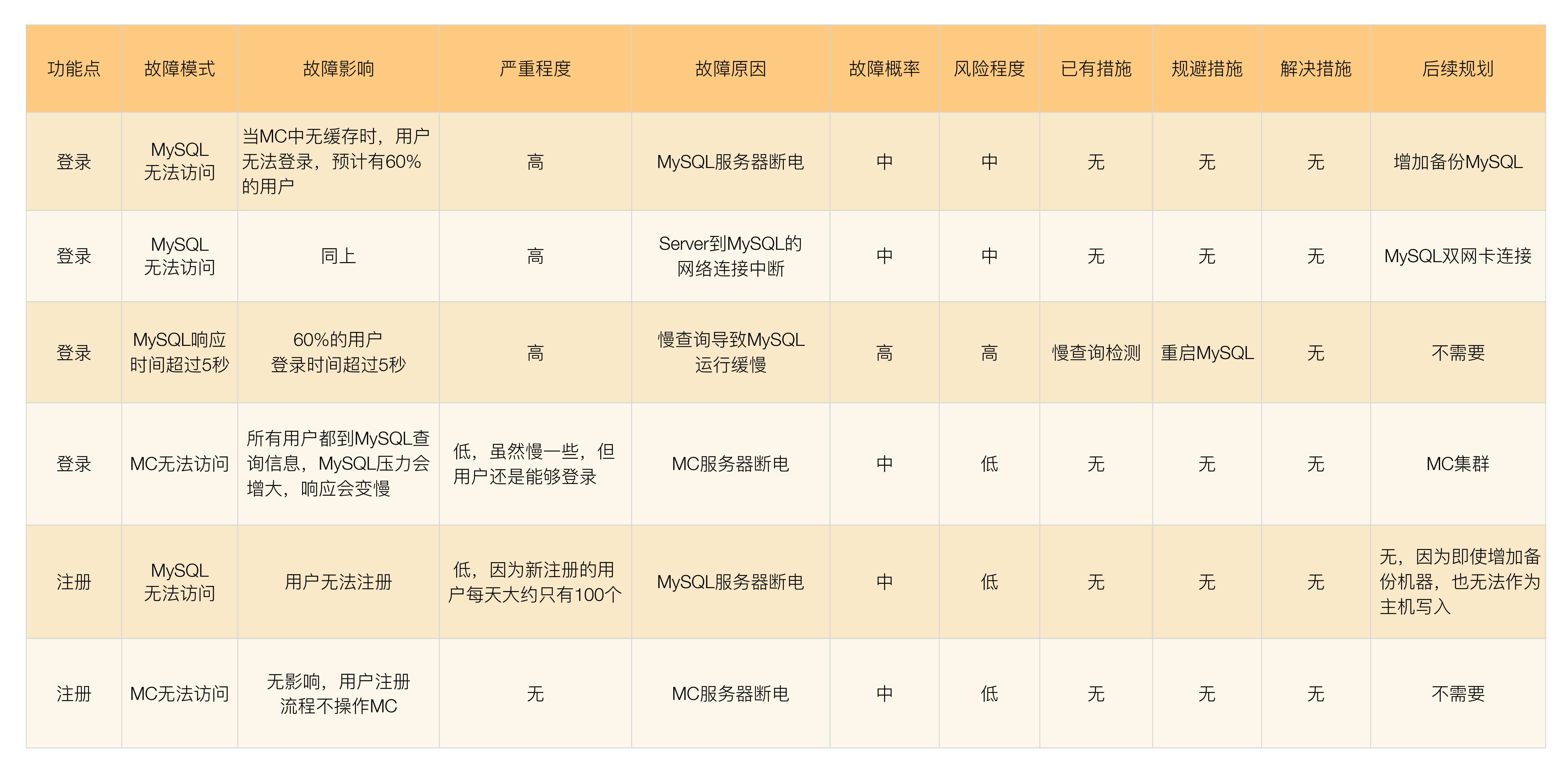
FMEA #
FMEA 方法主要用于分析故障模式和影响。
实施方法
- 给出初始的架构设计图
- 假设架构中某一部件发生故障
- 分析此故障对系统功能造成的影响
- 制作FMEA分析表,根据分析结果,判断是否可进行优化
FMEA 分析表
包含以下内容,各指标应尽量包含具体数字。
- 功能点:从用户角度而非技术组件角度,如注册是功能点而Redis不是
- 故障模式:包括故障点和故障形式。量化现象无需原因,如MySQL响应慢到3秒。
- 故障影响:量化故障影响,如20%用户不可用。
- 严重程度:致命、高、中、低、无
- 故障原因:
- 故障概率:高、中、低
- 风险程度:风险程度 = 严重程度 × 故障概率
- 已有措施:告警、自恢复、容错等
- 规避措施:技术手段、管理手段
- 解决措施:无法解决的才采用规避措施
- 后续规划:
实例
多机房部署 #
1、同城双活
A机房联通,B机房电信,机房之间专线连接。核心思想是系统数据尽可能同机房读写,但也支持跨机房写入。
- 主库:放在机房A中。A机房和B机房的数据都会写入A机房中。
- 从库:机房A和机房B各放一个。查询请求优先查询本机房的从库。
- 主从切换:机房A故障后机房B的从库提升为主库。
- 缓存:优先查同机房的缓存,未命中则查询同机房的从库。更新时同时写双机房的缓存以缓解主从同步的延迟。
- 服务注册:注册中心可以部署在单机房。服务注册时使用"机房名+服务名"作为注册名,不同机房的服务组成不同的服务组。每个机房的服务只订阅当前服务组的接口。
2、异地多活
异地多活机房间距离应该比较远,如上海和北京,此时同城双活的跨机房写数据库方案就不适用了。核心思想是读写同机房,跨机房异步同步。
- 数据只写入本机房数据库,然后同步到异地机房。实现方式如下:
- 数据库采用主从复制,一个机房主库,异地机房从库。
- 基于消息队列同步。
- 用户基于地理位置分片,读写都在同一机房。
Devops #
灰度发布 #
- 金丝雀发布:先发布几台,正常后将剩余的一起发布
- 滚动发布:先发布几台,正常后再发布下一批次
- 双服务器组蓝绿发布:在新节点发布新版本,然后一次性切换
- 双服务器组蓝绿金丝雀发布:在新节点发布新版本,先切换几台,正常后一起切换
- 双服务器组蓝绿滚动发布
- 功能开发发布:开关打开后走新逻辑
- A/B发布:将一定用户切换到新版本,正常后全部切换
监控系统 #
监控指标
QPS、PV、RT、错误率、CPU利用率、CPU负载、内存占用率、硬盘空间等。
监控工具
- 日志监控:ELK
- 调用链监控:CAT、Skywalking
- 指标监控:Promethus+Gafana
- 业务监控:自行开发+Gafana
项目上线自查手册 #
SQL语句
- 表关联数
- 是否包含复杂条件
- 每次返回行数
- 一天执行次数
- 是否使用缓存
后台任务
- 幂等性
- 是否支持自恢复
- 执行频率
- 每次数据量
- 每次执行时间
服务调用
- 幂等性
- 依赖的服务不可用时
消息
- 幂等性
- 发送失败重试
- 消费失败重试
缓存
- 缓存占用空间
- 有效期
安全性
- 敏感信息存储和展示
- 数据传递安全性
- 日志脱敏
- 密钥管理方案
版本升级
- 老数据在新服务上
- 新数据在老服务上